Reinforcement Learning
Table of Contents
Reinforcement learning (RL) (Sutton, 1998) is all about the interaction between an agent and its environment, where learning occurs through trial-and-error. The agent observes the current state of the environment, takes actions based on these observations, and influences new possible state configurations while receiving rewards based on its actions. The primary objective is to maximize cumulative rewards, which drives the agent’s sequence of decisions towards achieving specific goals, such as escaping from a maze, winning an Atari (Mnih. 2013) , or defeating the world champion of Go (Silver, 2016). But how does the agent learn to act effectively to achieve its goal? RL algorithms are designed to maximize the total rewards obtained by the agent, thereby guiding its actions towards these objectives.
In this post, we will introduce the essential concepts of RL required to implement these agents. We will specifically focus on model-free RL, where the agent learns to act without constructing a model of its environment, as opposed to model-based RL, which involves such modeling. The goal is to design agents that learn to perform well solely by consuming experiences from their environment. By understanding the fundamentals of designing such agents, we will explore policy optimization methods, such as REINFORCE and PPO, which are used to refine the agent’s behavior.
With the knowledge gained from this chapter, we will be equipped to set-up and implement this framework under popular research environment such as ATARI pong.
The Framework for Learning to Act
The starting point for designing agents that learn to act is the Markov Decision Process (MDP) framework \cite{Sutton1998}. An MDP is a mathematical object that describes the interaction between the agent and the environment. This interaction is characterized by a tuple \(\langle \mathcal{S}, \mathcal{A}, P, R, \rho_{0}, \gamma \rangle\), where:
- \(\mathcal{S}\), state space, set of possible states in the environment.
- \(\mathcal{A}\), action space, set of possible actions available to the agent.
- \(P: \mathcal{S}\times\mathcal{A}\rightarrow\Delta(\mathcal{S})\), transition probability distribution, which gives the probability of the environment for transitioning to a new state \(s_{t+1}\) with a reward \(r_t\) given the current state \(s_{t}\) and action \(a_{t}\).
- \(R: \mathcal{S}\times\mathcal{A}\rightarrow\mathbb{R}\), reward function, which provides a scalar feedback signal \(r_{t}\) (aka reward) to the agent after taking an action \(a_{t}\) and reaching the subsequent state \(s_{t+1}\).
- \(\rho_{0}\), **initial state distribution**, which determines the probability of the agent starting in a particular state.
- \(\gamma\in\left[0, 1 \right]\) is the discount factor, which determines the importance of future rewards.
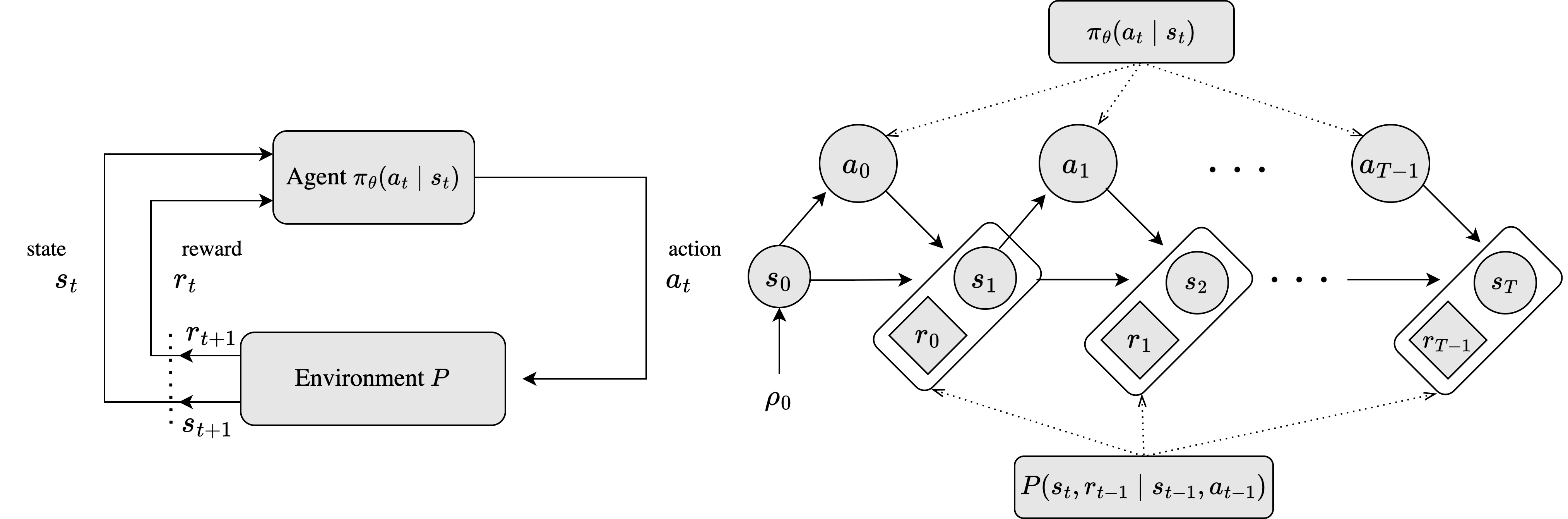
Figure 1. Left: A loop representation of a Markov Decision Process (MDP). Right: An unrilled MDP depecting an episodic case with a finite horizon \\(T\\) and a parameterized policy \\(\pi\_{\theta}\\).
Markov Decision Processes generate sequences of state-action pairs, or trajectories \(\tau\), starting from an initial state \(s_{0}\sim\rho_{0}\). The agent’s behavior is determined by a policy \(\pi:\mathcal{S}\rightarrow\Delta(\mathcal{A})\), which maps states to a probability distribution over actions. An action \(a_{0}\sim\pi(s_{0})\) is chosen, leading to the next state \(s_{1}\) according to the transition distribution \(P\), and a reward \(r_{0}=R(a_{0}, s_{0})\) is received. This cycle repeats iteratively, with the agent selecting actions, transitioning through states, and receiving rewards, as shown on the left side of Figure 1. Thus, the trajectory \(\tau\) encapsulates the dynamic sequence of state-action pairs resulting from the agent’s interaction with its environment.
The process can continue indefinitely, known as an infinite horizon, or be confined to episodes that end in the terminal state \(s_{T}\), referred to as episodic tasks, such as winning or losing a game, as illustrated on the right side of Figure 1. It is important to note that the transition to the next state depends only on the current state and action, not on the sequence of prior events. This characteristic is known as the _Markov property_, which states that the future and the past are conditionally independent, given the present (_memoryless_). In this work, we focus on the episodic setting, where the trajectory begins at \(s_{0}\) and concludes at \(s_{T}\), with a finite horizon \(T\). Therefore, the trajectory \(\tau\) is defined as \(\tau = (s_{0}, a_{0}, \dots, s_{T-1}, a_{T-1}, s_{T})\), summarizing the agent’s behavior throughout the episodic task.
In reinforcement learning, the primary goal is for the agent to develop a behavior that maximizes the expected return from its actions results within the environment. This concept of maximization is formalized through the objective function \(\mathcal{J}_{\text{RL}}(\theta)\), which aims to maximize the expected return over a collection of trajectories \( {\tau^{(i)}}_{1:N} \) generated by the policy \(\pi\), commonly referred to as “policy rollouts”. The term “rollout” is used to describe the process of simulating the agent’s behavior in the environment by executing the policy \(\pi\) and observing the resulting trajectory \(\tau\). The objective function is defined as follows:
\[ \begin{equation} \mathcal{J}_{\text{RL}}=\underset{\pi}{\text{maximize }} \mathbb{E}_{\tau\sim\pi}\left[R(\tau)\right] \end{equation} \]
The return over a trajectory \(\tau\) is defined as the accumulated discounted rewards of the trajectory, \(R(\tau) = \sum_{t=0}^{T-1}\gamma^{t}r_{t}\). The reward signals \(r_{t}\) are the inmmediate effect of taking the actions, and the return is the cumulative rewards obtained during the trajectory, considering a discount factor \(\gamma\), which gives more importance to the rewards of nearer actions than to future rewards.
Policy Optimization
In reinforcement learning there are different approaches to solve the MDP formulated in the previous section, which are summarized in Figure 2. The most common are value-based methods and policy-based methods. In value-based methods, the agent learns which state is more valuable and take action that leads to it. In policy-based methods, the agent learns a policy that directly maps states to actions. In this work we will focus on the latter methods, specifically in policy gradients.
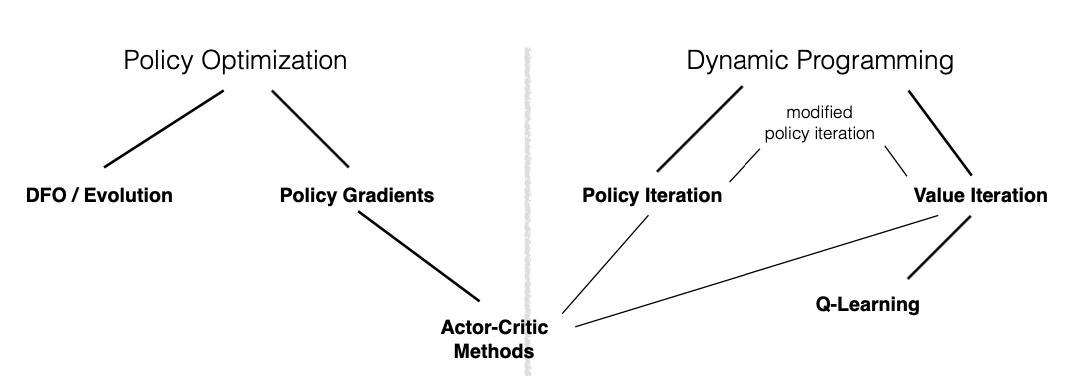
Other approaches for finding a policy is by non solving the MDP, but by directly optimizing the policy. This is the case of derivative free optimization (DFO), or evolutionary algorithms, in which the policy is parameterized by a vector \(\theta\), and the agent explores the space of parameters by searching. Nothing of the temporal structure and actions of the MDPs are considered in this kind of solution.
Policy gradient methods provide a way to reduce reinforcement learning to stochastic gradient descent, by providing a connection between how function approximation is solved in supervised learning settings, but with the key diffrence that the dataset is collected using the model itself plus a reward signal that acts as a “label”.
Learning the Policy
The starting point is to think of trajectories as units of learning instead of individual observations (i.e., actions). What dynamics generate a trajectory? Given a policy \(\pi_{\theta}\), represented as a function with parameter \(\theta\in \mathbb{R}^{d}\), whose input is a representation of the state and whose output is action selection probabilities, we can deploy the agent into its environment at an initial state \(s_0\) and observe its actions in inference mode or _evaluation phase_ \citep{sutton1999policy}. The agent continuously promotes actions based on the current state \(s_{t}\) until the episode ends in a terminal state, when \(t=T\). At this point, we can determine if the goal was accomplished, such as winning the ATARI Pong game, or generating aesthetically pleasing samples from a diffusion model. The returns are the scalar value that assets perfomance whether we have achieved the ultimate goal, effectively acting as a “proxy” of a label for the overall trajectory. Thus, the trajectory serves as our unit of learning, and the remaining task is to establish the feedback mechanism for the _learning phase_.
Intuitivelly, we want to collect the trajectories and make the good trajectories and actions more probable, and push the actions towards betters actions.
Mathematically, we aim to perform stochastic optimization to learn the agent’s parameters. This involves obtaining gradient information from sample trajectories, with performance assessed by a scalar-value function (i.e. reward). The optimization is stochastic because both the agent and the environment contain elements of randomness, meaning we can only compute estimates of the gradient. Crucially, we are estimating the gradient of the expected return with respect to the policy parameters. To address this, we employ Monte Carlo Gradient Estimation \citep{mohamed2020monte}, specifically using the score function method. From a machine learning perspective, this involves dealing with the stochasticity of the gradient estimates, \(\hat{g}\), and using gradient ascent algorithms to update the policy parameters based on these estimates, along with a learning rate \(\alpha\) to control the step size of the optimization process,
\begin{equation}\label{eqn:gradient-ascent} \theta \leftarrow \theta + \alpha \hat{g}_{N}. \end{equation}
Gradient Estimation via Score Function
The gradient estimation can be obtained using the score function gradient estimator. Let’s introduce the following probability objective \(\mathcal{F}\), defined in the ambient space \(\mathcal{X}\in\mathbb{R}^n\) and with parameters \(\theta\in\mathbb{R}^n\),
\[ \begin{equation}\label{eqn:probability-objective} \mathcal{F}(\theta) = \int_{\mathcal{X}} p(\mathrm{x; \theta})f(\mathrm{x})~d\mathrm{x} = \mathbb{E}_{p(\mathrm{x};\theta)}\left[f(\mathrm{x})\right]. \end{equation} \]
Here, \(f\) is a scalar-valued function, similar to how the reward is represented in the reinforcement learning setting. The score function is the derivative of the log probability distribution \(\nabla_{\theta}\log p(\mathrm{x};\theta)\) with respect to its parameters \(\theta\). We can use the following identity to establish a connection between the score function and the probability distribution \(p(\mathrm{x};\theta)\),
\begin{equation}\label{eqn:log-derivative-trick-expression}
\begin{split}
\nabla_\theta\log p(\mathrm{x};\theta) &= \frac{\nabla_{\theta}p(\mathrm{x}; \theta)}{p(\mathrm{x};\theta)} \\
p(\mathrm{x};\theta) \nabla_{\theta}\log p(\mathrm{x};\theta) &= \nabla_{\theta}p(\mathrm{x};\theta).
\end{split}
\end{equation}
Therefore, taking the gradient of the objective \(\mathcal{F}(\theta)\) with respect to the parameter \(\theta\), we have
\[
\begin{equation}\label{eqn:score-function-gradient-objective}
\begin{split}
g = \nabla_{\theta} \mathbb{E}_{p(\mathrm{x};\theta)}\left[f(\mathrm{x})\right] &= \nabla_{\theta}\int_{\mathcal{X}} p(\mathrm{x};\theta) f(\mathrm{x}) d\mathrm{x} \\
&= \int_\mathcal{X} \nabla_{\theta}~p(\mathrm{x};\theta)f(\mathrm{x})d\mathrm{x} \\
&= \int_{\mathcal{X}} p(\mathrm{x};\theta)\nabla_{\theta}\log p (\mathrm{x}; \theta) f(\mathrm{x})d\mathrm{x} \\
&= \mathbb{E}_{p(\mathrm{x};\theta)}\left[f(\mathrm{x})\nabla_{\theta} \log p(\mathrm{x};\theta) \right]
\end{split}
\end{equation}
\]
The use of the log-derivative rule on the above equation to introduce the score function is also known as the log-derivative trick. Now, we can compute an estimate of the gradient, \(\hat{g}\), using Monte Carlo estimation with samples from the distribution \(p(\mathrm{x};\theta)\) as follows:
\[ \begin{equation}\label{eqn:score-function-gradient-estimator} \hat{g}_{N} = \frac{1}{N}\sum_{i=1}^{N}f\left(\hat{\mathrm{x}}^{(i)}\right) \nabla_{\theta}\log p\left(\hat{\mathrm{x}}^{(i)};\theta\right). \end{equation} \]
We draw \(N\) samples \(\hat{\mathrm{x}}\sim p(\mathrm{x};\theta)\), compute the gradient of the log-probability for each sample, and multiply by the scalar-valued function \(f\) evaluated at the sample. The average of these terms is an unbiased estimate of the gradient of the objective \(g\), which we can use for gradient ascent.
There are two important points to mention about the previous equation.
- The function \(f\) can be any arbitrary function we can evaluate on \(\mathrm{x}\). Even if \(f\) is non-differentiable with respect to \(\theta\), it can still be used to compute the gradient estimation \(\hat{g}\).
- The expectation of the score function is zero, meaning that the gradient estimator is unbiased
\[
\begin{equation}\label{eqn:score-function-expectation-zero}
\begin{split}
\mathbb{E}_{p(\mathrm{x};\theta)}\left[\nabla_{\theta}\log p(\mathrm{x};\theta)\right]
&= \int_{\mathcal{X}}p(\mathrm{x};\theta)\nabla_{\theta}\log p(\mathrm{x}; \theta) d\mathrm{x} \\
&= \int_{\mathcal{X}} p(\mathrm{x};\theta)\frac{\nabla_{\theta} p(\mathrm{x}; \theta)}{p(\mathrm{x};\theta)}d\mathrm{x} \\
&= \int_{\mathcal{x}}\nabla_{\theta}p(\mathrm{x};\theta)d\mathrm{x} \\
&= \nabla_{\theta}\int_{\mathcal{X}} p(\mathrm{x}; \theta)d\mathrm{x} = \nabla_{\theta} 1 =0.
\end{split}
\end{equation}
\]
The last point is particularly useful because we can replace \(f\) with a shifted version given a constant \(\beta\), and still obtain an unbiased estimate of the gradient, which can be beneficial for the optimization task:
\[ \hat{g}_{N} = \mathbb{E}_{p(\mathrm{x}_{\theta})}\left[(f(\mathrm{x}) - \beta) \nabla_{\theta} \log p(\mathrm{x}; \theta)\right]. \]
Using a baseline function to determine \(\beta\), that does not depend on the parameter \(\theta\), can reduce the variance of the estimator \citep{mohamed2020monte}. The baseline function, which satisfies the property that the score function expectation is zero, can be any function independent of \(\theta\). When a baseline is chosen to be close to the scalar-valued function \(f\), it effectively reduces the variance of the estimator. This reduction in variance helps stabilize the updates by minimizing fluctuations in the gradients estimates, leading to more reliable and efficient learning.
Vanilla Policy Gradient, aka REINFORCE
The REINFORCE algorithm \citep{williams1992simple} translates the previous derivation of gradient estimation via the score function into reinforcement learning terminology. This is the earliest member of the Policy Gradient family (Figure~\ref{fig:rl-model-free-taxonomy}), where the objective is to maximize the expected return of the trajectory \(\tau\) under a policy \(\pi\) parameterized by \(\theta\) (e.g., a neural network). At each state \(s_{t}\), the agent takes an action \(a_{t}\) according to the policy \(\pi\), which generates a probability distribution over actions \(\pi(a_{t}\mid s_{t};\theta)\). Here, we will use the notation \(\pi_{\theta}(\cdot)\) instead of \(\pi(\cdot;\theta)\).
As we mentioned in previous section, a trajectory \(\tau\) represents the sequence of state-action pairs resulting from the agent’s interaction with its environment. From the initial state \(s_{0}\) to the terminal state \(s_{T}\), the trajectory \(\tau\) is a sequence of states and actions, \(\tau = (s_{0}, a_{0}, \dots, s_{T-1}, a_{T-1}, s_{T})\), which describes how the agent acts during the episodic task. Let \(p_{\theta}(\tau)\) be the probability of obtaining the trajectory under the policy \(\pi_{\theta}\).
We thus have a distribution of trajectories. Remember that the trajectory \(\tau\) is the learning unit for our policy \(\pi_{\theta}\), as it tells us if the consequences of each action led to a favorable final outcome on the terminal state \(s_{T}\) (e.g. win/lose). The goal is to maximize the exptected return of the trajectories on average, and the return \(R(\tau)\) could be the cumulative rewards obtained during the ***episode*** or the discounted rewards. The expected return is given by the following expression:
\[ \begin{equation}\label{eqn:rl-objective} \mathcal{J}(\theta)_{\text{RL}}=\mathbb{E}_{\tau\sim p_{\theta}(\tau)}\left[R(\tau)\right]. \end{equation} \]
This is the objective we want to maximize, which is a particular case of Equation~(\ref{eqn:probability-objective}) with the scalar-valued function \(f(\mathrm{x}) = R(\tau)\), representing the return of the trajectory. Let’s use the techniques from the previous section to compute the gradient of the objective in Equation~(\ref{eqn:rl-objective}) with respect to the policy parameter \(\theta\). The gradient estimation is given by:
\[
\begin{equation}\label{eqn:rl-gradient-estimator-vanilla}
\nabla_{\theta} \mathbb{E}_{\tau\sim p_{\theta}(\tau)}[R(\tau)] = \mathbb{E}_{\tau\sim p_{\theta}(\tau)}\left[R(\tau)\nabla_{\theta}\log p_{\theta}(\tau)\right].
\end{equation}
\]
What is \(p_{\theta}(\tau)\) exactly? Given that the trajectory is a sequence of states and actions, and assuming the Markov property imposed by the MDP, the probability of the trajectory is defined as follows:
\[
\begin{equation}\label{eqn:trajectory-probability-expandedi}
\begin{split}
p_{\theta}(\tau) &= p_\theta(s_{0}, a_{0}, s_{1}, a_{1}, \dots, s_{T-1}, a_{T-1}, s_{T}) \\
&= \rho(s_0)~\prod_{t=0}^{T-1} \pi_{\theta}(a_{t}\mid s_{t})~P(s_{t+1}, r_{t}\mid a_{t}, s_{t}).
\end{split}
\end{equation}
\]
In the above expression, \(\rho(s_{0})\) denotes the distribution of initial states, while \(P(s_{t+1}, r_{t}\mid a_{t}, s_{t})\) represents the transition model, which updates the environment context based on the action \(a_{t}\) taken in the current state \(s_{t}\). A crucial step in estimating the gradient is computing the logarithm of the trajectory probability. Following this, we calculate the gradient with respect to the policy parameter \(\theta\),
\begin{equation}\label{eqn:trajectory-gradient-score}
\begin{split}
\log p_{\theta}(\tau) &= \log \rho(s_0) + \sum_{t=0}^{T-1}\log \pi_{\theta}(a_{t}\mid s_{t}) + \log P(s_{t+1}, r_{t}\mid a_{t}, s_{t}) \\
\nabla_{\theta}\log p_{\theta}(\tau) &= \log \nabla_{\theta}\rho(s_0) + \sum_{t=0}^{T-1}\nabla_{\theta}\log \pi_{\theta}(a_{t}\mid s_{t}) + \log\nabla_{\theta} P(s_{t+1}, r_{t}\mid a_{t}, s_{t}) \\
\nabla_{\theta} \log p_{\theta}(\tau) &= \sum_{t=0}^{T-1}\nabla_{\theta}\log \pi_{\theta}(a_{t}\mid s_{t}).
\end{split}
\end{equation}
The distribution of initial states and the transition probabilities are disregarded because they are independent of \(\theta\), thereby simplifying significantly the computations needed for gradient estimation. By substituting the final expression from Equation~(\ref{eqn:trajectory-gradient-score}) into the gradient estimation of the objective in Equation~(\ref {eqn:rl-gradient-estimator-vanilla}), we derive the REINFORCE gradient estimator
\[
\begin{equation}\label{eqn:reinforce-gradient-estimator}
\begin{split}
g &= \nabla_{\theta}\mathbb{E}_{\tau\sim p_{\theta}(\tau)}[R(\tau)] \\
&= \mathbb{E}_{\tau\sim p_{\theta}(\tau)}\left[\sum_{t=0}^{t-1} \nabla_{\theta}\log \pi_{\theta} (a_t\mid s_t) R(\tau)\right] \\
\hat{g} &= \frac{1}{\mid\mathcal{D}^{\pi_{\theta}}\mid}\sum_{\tau\in\mathcal{D}^{\pi_{\theta}}}\left[~\sum_{t=0}^{t-1} \nabla_{\theta} \log\pi_{\theta} (a_{t}\mid s_{t}) R(\tau) \right].
\end{split}
\end{equation}
\]
The core concept is to collect a set of trajectories \(\mathcal{D}^{\pi_{\theta}}\) under the policy \(\pi_{\theta}\) and update the policy parameters \(\theta\) to increase the likelihood of high-reward trajectories while decreasing the likelihood of low-reward ones, as illustrated in Figure~\ref{fig:anatomy-rl-trajectories}. This trial-and-error learning approach, described in Algorithm 1, repeats this process over multiple iterations, reinforcing successful trajectories and discouraging unsuccessful ones, thus encoding the agent’s behavior in its parameters.
- Initialize policy \( \pi_{\theta} \), set learning rate \( \alpha \)
- For \( \text{iteration}=0, 1, 2, \dots, N \):
- Collect a set of trajectories \( \mathcal{D}^{\pi_{\theta}}=\{\tau^{(i)}\} \) by sampling from the current policy \( \pi_{\theta} \)
- Calculate the returns \( R(\tau) \) for each trajectory \( \tau\in\mathcal{D}^{\pi_{\theta}} \)
- Update the policy: \( \theta \leftarrow \theta + \alpha \left(\frac{1}{|\mathcal{D}^{\pi_{\theta}}|}\sum_{\tau\in\mathcal{D}^{\pi_{\theta}}}\left[\sum_{t=0}^{T-1}\nabla_{\theta}\log\pi_{\theta}(a_{t}| s_{t})R(\tau)\right]\right) \)
Reducing the variance of the estimator. Using two techniques, reward-to-go and baseline, we can improve the quality of the gradient estimator in Equation~(\ref{eqn:reinforce-gradient-estimator}).
The reward-to-go technique is a simple trick that can reduce the variance of the gradient estimator by taking advantage of the temporal structure of the problem. The idea is to weight the gradient of the log-probability of an action \(a_{t}\) by the sum of rewards from the current timestep \(t\) to the end of the trajectory \(T-1\). This way, the gradient of the log-probability of an action is only weighted by the consequence of that action on the future rewards, removing terms that do not depend on \(a_{t}\). Let’s introduce this technique by using the gradient estimation in Equation~(\ref{eqn:reinforce-gradient-estimator}) and replacing \(R(\tau)\) naively using the sum of total trajectory reward **\footnote**{The same applies for discounted returns or other kind of returns \(R(\tau)\).}
\[
\begin{equation}\label{eqn:reinforce-gradient-reward-to-go}
\begin{split}
\hat{g} &= \frac{1}{\mid\mathcal{D}^{\pi_{\theta}}\mid}\sum_{\tau\in\mathcal{D}^{\pi_{\theta}}}\left[\sum_{t=0}^{T-1} \nabla_{\theta} \log\pi_{\theta} (a_{t}\mid s_{t})\sum_{t=0}^{T-1} r_{t}\right] \\
&= \frac{1}{\mid\mathcal{D}^{\pi_{\theta}}\mid}\sum_{\tau\in\mathcal{D}^{\pi_{\theta}}}\left[~\sum_{t=0}^{T-1} \nabla_{\theta} \log\pi_{\theta} (a_{t}\mid s_{t}) \left( \sum_{t=0}^{t-1} r_{t} + \sum_{t'=t}^{T-1} r_{t'} \right)\right] \\
&= \frac{1}{\mid\mathcal{D}^{\pi_{\theta}}\mid} \sum_{\tau\in\mathcal{D}^{\pi_{\theta}}} \left[ ~\sum_{t=0}^{T-1} \nabla_{\theta} \log\pi_{\theta} (a_{t}\mid s_{t}) \sum_{t'=t}^{T-1} r_{t'}\ \right] .
\end{split}
\end{equation}
\]
As we saw at the end of Section~\ref{sec:gradient-estimation-score-function}, it is possible to reduce the variance of the gradient estimator by using a baseline function, \(b(s_{t})\), without biasing the estimator. However, is the expectation of the score still unbiased in this setting?
\[ \begin{equation}\label{eqn:reinforce-gradient-estimator-baseline} \begin{split} \nabla_{\theta}\mathbb{E}_{\tau\sim p_{\theta}(\tau)} &= \mathbb{E}_{\tau\sim p_{\theta}(\tau)} \left[\sum_{t=0}^{T-1}\nabla_{\theta}\log\pi_{\theta}(a_{t}\mid s_{t}) \left(\sum_{t'=t}^{T-1} r_{t'}-b(s_{t'}) \right)\right]. \end{split} \end{equation} \]
The proof follows a similar argument as shown in Equation~(\ref{eqn:score-function-expectation-zero}), with the key difference being that the expectation is taken with respect \(p_{\theta}(\tau)\), which is a sequence of random variables. By leveraging the linearity of the expectation property, we can focus on a single term at step \(t\) of Equation~(\ref{eqn:reinforce-gradient-estimator-baseline}) to demonstrate that the baseline does not affect the expectation of the score function. We split the trajectory sequence \(\tau\) at step \(t\) into: \(\tau_{0:t}\) and \(\tau_{t+1:T-1}\), and then expand it into state-action pairs **\footnote**{A criterion used when splitting the trajectory is that state-action pairs are formed given that \(s_{t}\) is a consequence of action \(a_{t-1}\), and taking action \(a_{t}\) results in state \(s_{t+1}\). Notice both expectations from step 1 and 2 in Equation~(\ref{eqn:reinforce-baseline-unbiased}).}
\[
\begin{equation}\label{eqn:reinforce-baseline-unbiased}
\begin{split}
\mathbb{E}_{\tau\sim p_{\theta}(\tau)}\left[\nabla_{\theta}\log\pi_{\theta}(a_t\mid s_t) b(s_t) \right] &= \mathbb{E}_{\tau_{(0:t)}}\left[\mathbb{E}_{\tau_{(t+1:T-1)}}\left[ \nabla_{\theta}\log \pi_{\theta}(a_{t}\mid s_{t})b(s_{t})\right]\right] \\
&= \mathbb{E}_{s_{0:t}, a_{0:t-1}}\left[\mathbb{E}_{s_{t+1:T}, a_{t:T-1}}\left[ \nabla_{\theta}\log \pi_{\theta}(a_{t}\mid s_{t})b(s_{t})\right]\right] \\
&= \mathbb{E}_{s_{0:t}, a_{0:t-1}}\left[b(s_{t})\mathbb{E}_{s_{t+1:T}, a_{t:T-1}}\left[ \nabla_{\theta}\log \pi_{\theta}(a_{t}\mid s_{t})\right]\right] \\
&= \mathbb{E}_{s_{0:t}, a_{0:t-1}}\left[b(s_{t})\mathbb{E}_{a_{t}}\left[ \nabla_{\theta}\log \pi_{\theta}(a_{t}\mid s_{t})\right]\right] \\
&= \mathbb{E}_{s_{0:t}, a_{0:t-1}}\left[b(s_{t})\nabla_{\theta}\mathbb{E}_{a_{t}}\left[\log \pi_{\theta}(a_{t}\mid s_{t})\right]\right] \\
&= \mathbb{E}_{s_{0:t}, a_{0:t-1}}\left[b(s_{t})\nabla_{\theta}1\right] \\
&= 0.
\end{split}
\end{equation}
\]
We can remove irrelevant variables from the expectation over the portion of the trajectory \(\tau_{(t+1):(T-1)}\) because we are focusing on the term at step \(t\). The only relevant variable is \(a_{t}\), and the expectation \(\mathbb{E}_{a_{t}}\log\pi_{\theta}(a_{t}\mid s_{t})\) is 1. Given that the gradient with respect to \(\theta\) of a constant is zero, and \(b(s_{t})\) is multiplying it, the effect of the baseline on the expectation is nullified. This argument can be applied to any other term in the sequence due to the linearity of the expectation. Therefore, we have proven that using a baseline also keeps the gradient estimator unbiased in the policy gradient setting.
Choosing an appropriate baseline is a critical decision in reinforcement learning \citep{foundations-deeprl-series-l3}, as different methods can offer unique strengths and limitations. Common baselines include fixed values, moving averages, and learned value functions.
- Constant baseline: \(b=\mathbb{E}\left[ R(\tau)\right]\approx \frac{1}{m}\sum_{i=1}^{m} R(\tau^{(i)})\).
- Optimal constant baseline: \( b=\frac{\sum_{i}(\nabla_{\theta} \log P_{\theta}(\tau^{(i)}))^{2} R(\tau^{(i)})}{\sum_{i}(\nabla_{\theta}\log P_{\theta}(\tau^{(i)}))^{2}}\).
- Time-dependent baseline: \(b_{t}=\frac{1}{m} \sum_{i=1}^{m} \sum_{k=t}^{T-1} R(s_{k}^{(i)}, a_{k}^{(i)})\).
- State-dependent expected return: \(b(s_{t}) = \mathbb{E}\left[r_{t} + r_{t+1} + r_{t+2} + \dots + r_{T-1}\right] = V^{\pi}(s_{t})\).
The control variates method can significantly reduce estimator variance, enhancing the stability and performance of RL algorithms \cite{NIPS2001_584b98aa}. Despite the nuances and differences among baseline methods, the primary concept is the advantage, shown in Equation~(\ref{eqn:pg-objective-with-value-baseline}), which refers to increase log probabilities of action \(a_{t}\) proportionally to how much its returns, \(r_{t}\), are better than the expected return under the current policy, which is determined by the value function \(V^{\pi}(s_{t})\)
\[ \begin{equation}\label{eqn:pg-objective-with-value-baseline} \mathbb{E}_{\tau\sim p_{\theta}(\tau)} \left[\sum_{t=0}^{T-1}\nabla_{\theta}\log\pi_{\theta}(a_{t}\mid s_{t}) \left(\underbrace{\sum_{t'=t}^{T-1} R(a_{t'}, s_{t'}) - V^{\pi}(s_{t})}_{\text{advantage}} \right) \right]. \end{equation} \]
What remains is how do we get estimates for \(V^{\pi}\) in practice.
Actor-Critic Methods
Actor-Critic referred to learn concurrently models for the policy and the value function. This methods are more data efficient because they amortize the samples collected \(\mathcal{D}^{\pi_{\theta}}\) used for Monte Carlo estimations while reducing the variance of the gradient estimator. The actor controls how the agent behaves—by updating the policy parameters \(\theta\) as we see in previous sections—whereas the critic measures how good the taken action is, and could be a state-value (\(V\)) or action-value (\(Q\)) \footnote{Action-value function (\(Q\)) refers to the value of take action \(a\) on state \(s\) under a policy \(\pi\).} function. Notice that we are combining in some way both approaches for solving MDPs as is depicted in Figure~\ref{fig:rl-model-free-taxonomy}.
We are introducing a new function approximator for the value function, \(V_{\phi}(s_{t})\), where \(\phi\) are the parameters of the value function
\[ \begin{equation}\label{eqn:actor-critic-objective} \mathbb{E}_{\tau\sim p_{\theta}(\tau)} \left[\sum_{t=0}^{T-1}\nabla_{\theta}\log\pi_{\theta}(a_{t}\mid s_{t}) \left( \sum_{t'=t}^{T-1} R(a_{t'}, s_{t'}) - V_{\phi}^{\pi}(s_{t}) \right) \right]. \end{equation} \]
The objective is to minimize the mean squared error (MSE) between the estimated value and the empirical return, i.e. we are regress the value against empirical return in a supervised learning fashion
\[ \begin{equation}\label{eqn:value-function-loss} \phi \leftarrow \underset{\phi}{\arg\min} \frac{1}{\mid\mathcal{D}^{\pi_{\theta}}\mid}\sum_{\tau\in\mathcal{D}^{\pi_{\theta}}}\sum_{t=0}^{T-1}\left[\left(\left(\sum_{t'=t}^{T-1} R(a_{t'}, s_{t'})\right) - V_{\phi}(s_{t})\right)^2~\right]. \end{equation} \]
Algorithm 2 describes the steps for a REINFORCE variant with advantage , which combines the actor-critic approach with the traditioinoal REINFORCE algorithm. More components were introduced and can influence in the performance when the algorithm is implemented. For instance, the policy and value networks can share parameters or not. A useful study that make abalations and suggestions to pay attention when these algorithms are implemented is What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study (Andrychowicz, 2020 \cite{andrychowicz2020mattersonpolicyreinforcementlearning}).
- Initialize policy \( \pi_{\theta} \)
- Initialize value \( V_{\phi} \)
- Set learning rates \( \alpha_{a} \) and \( \alpha_{c} \)
- For \( \text{iteration}=0, 1, 2, \dots, N \):
- Collect a set of trajectories \( \mathcal{D}^{\pi_{\theta}}=\{\tau^{(i)}\} \) by sampling from the current policy \( \pi_{\theta} \)
- Calculate the returns \( R(\tau) \) for each trajectory \( \tau\in\mathcal{D}^{\pi_{\theta}} \)
- Update the policy:
- \( \theta \leftarrow \theta + \alpha_{a} \left(\frac{1}{|\mathcal{D}^{\pi_{\theta}}|}\sum_{\tau\in\mathcal{D}^{\pi_{\theta}}}\left[\sum_{t=0}^{T-1}\nabla_{\theta}\log\pi_{\theta}(a_{t}| s_{t})\left(\sum_{t'=t}^{T-1} R(a_{t'}, s_{t'}) - V_{\phi}^{\pi_{\theta}}(s_{t})\right)\right]\right) \)
- Update the value:
- \( \phi \leftarrow \phi + \alpha_{c} \left(\frac{1}{|\mathcal{D}^{\pi_{\theta}}|}\sum_{\tau\in\mathcal{D}^{\pi_{\theta}}}\left[\sum_{t=0}^{T-1}\left(\sum_{t'=t}^{T-1} R(a_{t'}, s_{t'}) - V_{\phi}^{\pi_{\theta}}(s_{t})\right)\nabla_{\phi}V_{\phi}^{\pi_{\theta}}(s_{t})\right]\right) \)
References
[1] Sutton, R. S. (2018). Reinforcement learning: An introduction. A Bradford Book.
[2] Mnih, V. (2013). Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602.
[3] Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., ... & Hassabis, D. (2017). Mastering the game of go without human knowledge. nature, 550(7676), 354-359.
[4] Schulman, J. (2016). Optimizing expectations: From deep reinforcement learning to stochastic computation graphs (Doctoral dissertation, UC Berkeley).