Deep Learning for Coders - notas capítulo 1
Primer post de una serie de públicaciones sobre la lectura y resolución del libro Deep Learning for Coders with fasti & PyTorch de Jeremy Howard & Sylvain Gugger. Resumen y notas sobre el capítulo 📝, pero también referencias a material adicional que complementan su lectura. Además se encuentran mis respuestas al cuestionario y preguntas de investigación propuestas al final del capítulo.
Breve historia redes neuronales
Se define Deep Learning a muy alto nivel como una técnica computacional para realizar predicciones en base datos usando redes neuronales compuestas de multiples capas. Cada una de estas capas recibe un input y entrega un output, así refinando los resultados a medida que la información avanza en la red. Hay un proceso de entrenamiento guiado por algún algoritmo que busca mínimizar el error (e.g. SGD, Adagrad, Adam) de las predicciones generadas por el modelo y el verdadero valor entregado por los datos. Estas redes neuronales profundas se utilizan en varios campos de investigación como Natural Language Processing (NLP), Computer Vision, Image Generation, Robotics, Recommendation Systems, entre otros.
Luego el capítulo construye una breve línea de tiempo sobre los modelos de redes neuronales.
- 1943: Warren McCulloh y Walter Pitts desarrollan el modelo matemático de una neurona artificial en el paper A logical Calculus of the Ideas Immanent in Nervous Activity.
- 1957: Frank Rossenblat implementa el primer modelo de neurona artificial llamado Perceptron con la capacidad de “aprender”.
- 1969: Marvin Minsky y Seymour Papert publican el libro Perceptron sobre el trabajo de Rossenblat. Demuestran que una capa de estas neuronas es incapaz de aprender funciones simples como XOR. Sin embargo, en el mismo libro, demuestran como subsanar este problema añadiendo más capas de neuronas (aka multilayer perceptron).
- 1970-1985: Disminución importante en investigaciones sobre redes neuronales, con la excepción de un grupo acotado de investigadores. En el último episodio de la temporada 2 del podcast The Robot Brains Podcast, entrevistan a Geoffrey Hinton, y cuenta una anéctoda sobre la presentación de una investigación que realizaba en 1973 que utilizaba redes neuronales. Luego de la presentación, y con una audiencia bastante escéptica, una de las pregunta que recibió Hinton fue porqué usaba esos métodos, cuando Minsky y Papert “habían dicho” que no servían (supuestamente en el libro Perceptron).
- 1986: Se pública el libro Parallel Distributed Processing (PDP) de varios tomos por David Rumelhart, James McClelland, y Cia. Basandose y profundizandose en los trabajos previos de Rossenblat + Minksky el libro formaliza aún más la teoría y aspectos de implementación.
- 2012: El grupo de Geoffrey Hington gana la competencia Imagenet disminuyendo de forma drástica el error del modelo versus la solución del resto de los participantes y de las certamenes anteriores.
Hay muchos más detalles y contribuciones en la historia de la Inteligencia Artificial y el uso de redes neuronales, Jürgen Schmidhuber ahonda en esto, ofreciendo una serie de detalles y referencias interesantes en el siguiente video estrenado en la conferencia AIJ a finales del año 2020.
¿Qué es Machine Learning?
El capítulo cita y comenta el ensayo Artificial Intelligence: A Frontier of Automation de Arthur L. Samuel (1962), quien acuñó el término machine learning y fue director de investigación en comunicaciones de IBM. El ensayo comienza dismitificando las consideraciones antropomórficas y afirmaciones grandilocuentes sobre el campo de la Inteligencia Artificial, y a la vez legitimando su validez e impacto como disciplina en la resolución de problemas espécificos como traducir automáticamente del ruso al inglés, capacidad de reconocer dígitos escritos a mano, o texto escrito de puño y letra, además de la resolución de juegos de mesa que permiten explorar el diseño de agentes con capacidad de búsqueda e inferencia. El ensayo también acota el scope en que opera la Inteligencia Artificial respecto al rol del computador, descartando lo que no es. Arthur plantea la analogía de que lo que distingue a un buen trabajador de uno no tan bueno, la capacidad del primero de investigar y aprender el cómo realizar la tarea, mientras el segundo debe ser guiado paso a paso en la resolución de esta. Esto significa que más allá de la complejidad del software–como cálcular el estrés producido por el viento sobre las alas de una avión– estaríamos frente a instrucciones detalladas previamente por un programador, y por lo tanto, sería una inteligencia empaquetada y entregada a la máquina.
“Programming a computer for such computations is, at best, a difficult task, not primarily because of any inherent complexity in the computer itself but, rather, because of the need to spell out every minute step of the process in the most exasperating detail. Computers, as any programmer will tell you, are giants morons, not giants brains” (Samuel, pag. 13)
El objetivo, y la idea de inteligencia artificial de Arthur, era especificar la tarea a la máquina y que esta pudiera encontrar por su cuenta la solución. Arthur formula ciertos requerimientos críticos para que una máquina tenga la capacidad de búscar soluciones, y lo hace dando el ejemplo de programar a un computador para que juegue damas. En esencia, una vez que uno tiene la representación de un tablero en el computador y las reglas que gobiernan el juego, este puede tomar acciones para generar movimientos y explorar las consecuencias de distintos estados del tablero. Sin embargo, veremos que la tarea de ir explorando las posibles secuencias de combinaciones hacía adelante es un camino sin fin, pensemos en las \(10^{170}\) configuraciones de tablero que representa el juego Go y que superan el número de átomos en el universo, un cometido imposible incluso para un computador. No se debe plantear la búsqueda en términos de objetivos secundarios (i.e. ir por un caballo, o dar este movimiento) sino de alguna otra forma.
It is here that we encounter the idea of machine learning. Suppose we arrange for some automatic means of testing the effectiveness of any current weight assignment in terms of actual performance and provide a mechanism for altering the weight assignment so as to maximize the performance. We need not go into the details of such a procedure to see that it could be made entirely automatic and to see that a machine so programed would “learn” from its experience (Samuel, pag. 17)

El diagrama contiene los conceptos a los que se refiere Arthur, una máquina dotada con un mécanismo de feedback automático, la experiencia se produce a través de comparar las etiquetas y predicciones basadas en características de los datos. Y luego la capacidad de asignar los pesos del programa para cambiar el estado del programa y guiar la búsqueda de soluciones en dirección a máximizar el desempeño (i.e. tableros ganadores). Utilizando este paradigma Arthur creo un programa para jugar damas que termino superando a uno de los campeones estatales en EEUU.
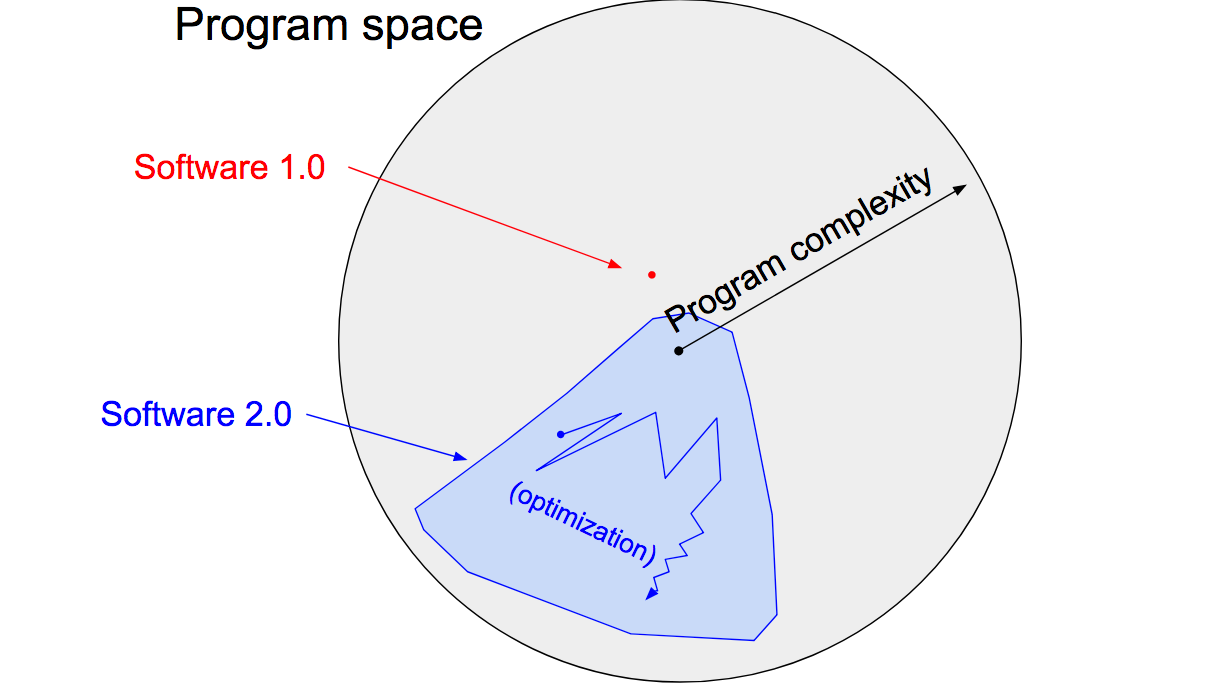
Una lectura complementaria que me recordó el ensayo, e interesante como mirada actualizada, es un post de Andrej Karpathy que nombra a la descripcción realizada por Arthur de la máquina averiguando las instrucciones como software 2.0. Eso sí, con la expección de que Karpathy limita el paradigma exclusivamente a redes neuronales.
“Neural networks are not just another classifier, they represent the beginning of a fundamental shift in how we develop software. They are Software 2.0” (Karpathy)
Karpathy se basa en la comparación de la forma tradicional de escribir programas, o software 1.0, en donde se diseña el set de instrucciones para desarrollar una solución, y donde cada línea escrita por el programador es producto de decisiones que darán forma a un punto dentro del espacio de posibles programas. Respecto a una red neuronal, o software 2.0, al cuál se le especifica un objetivo, a través de pares de input y output, además de un esqueleto de código que será la arquitectura del modelo y definirá el “espacio del programa” con los posibles detalles a modificar. La red neuronal a través de un proceso de ajuste de parámetros (i.e. weight assignment en palabras de Arthur), guíado por su mécanismo de evaluación (i.e. loss), explorará diferentes configuraciones dentro del espacio y se quedará con la solución–encapsulada en los valores de sus parámetros–que mejor satisfagá el criterio de evaluación. El diagrama a continuación aparece en el post y es una manera de ilustrar lo anterior:
Fuente: Software 2.0- Andrej Karpathy
“To make the analogy explicit, in Software 1.0, human-engineered source code (e.g. some .cpp files) is compiled into a binary that does useful work. In Software 2.0 most often the source code comprises 1) the dataset that defines the desirable behavior and 2) the neural net architecture that gives the rough skeleton of the code, but with many details (the weights) to be filled in. The process of training the neural network compiles the dataset into the binary — the final neural network.” (Karpathy)
Otro tema interesante tratado por Karpathy es que sí entendemos las redes neuronales no como un simple clasificador, sino como una nueva formar de pensar el desarrollo de programas, es posible observar de mejor manera patrones y tendencias que faciliten la creación de software 2.0. Igual como se utilizan un conjunto de herramientas para apoyar la creación de software 1.0 (i.e. IDE, versionamiento, package managers). Karpathy escribe que será natural disponer de un stack para la creación de software 2.0. Lo interesante es que desde la publicación del post el año 2017 hasta la fecha, han proliferado una serie de herramientas que constituyen parte del stack que Karpathy vislumbró. Por ejemplo, se nombra:
- El equivalente a un repositorio para albergar código de software 1.0 como GitHub -> En la actualidad contamos con el hub de datasets de HuggingFace, una implementación de lo que Karpathy describe “in this case repositories are datasets and commits are made up of additions and edits of the labels.”.
- Etiquetar o re-etiquetar inputs para definir el objetivo del programa. Proyectos como Snorkel se han creado con un enfoque centrado en los datos (weak supervision), donde para un conjunto de datos sin etiqueta, o sin una calidad de etiquetado garantizado, es posible utilizar heuristicas en base a juicio experto para etiquetar de forma programática (i.e. labeling function) los datos.
- Algo similar a package managers (e.g. pip, conda) pero con checkpoints de modelos ya entrenados. De nuevo, hub de modelos de HuggingFace que permite fácilmente importar modelos y usar transfer learning para adaptarlos a nuevas tareas. Esto bajo el parádigma software 2.0 sería usar un programa para escribir otro programa.
¿Qué es una red neuronal?
Una neurona es un producto punto entre un input (\(\boldsymbol x\)) y un set de parámetros (\(\boldsymbol w\)) más un coeficiente que se llama bias (\(\boldsymbol b\)). Al resultado de esta operación se le aplica una función de activación (\(\sigma(\cdot)\)), por lo que una neurona queda espeficada como:
\[ \hat{y}^{(1)} = \sigma(\boldsymbol w^{\top}\boldsymbol x + \boldsymbol b) \]
Si tenemos una red neuronal, organizamos conjuntos de neuronas capa por capa, por lo que la información input-output de esta va fluyendo por la red. Si concatenamos la información de dos neuronas, sería algo como:
\[\begin{equation} \begin{split} \hat{y}^{(2)} &= \sigma(\boldsymbol w^{\top}\sigma(\boldsymbol w^{\top}\boldsymbol x + \boldsymbol b) + \boldsymbol b) \\ &= \sigma(\boldsymbol w^{\top}\hat{y}^{(1)} + \boldsymbol b) \end{split} \end{equation}\]
Se le suele llamar hidden layers a las capas internas (i.e. diferentes al input y output del modelo) dado que su resultado no se observa de forma directa. Es posible continuar este encadenado de funciones para ir construyendo modelos con más capas. Sin embargo, analizando la expresión anterior, una red neuronal perfectamente se podría entender como un stack de regresiones logisticas.
Un punto importante es que una red neuronal no concatena un conjunto de neuronas como una simple cadena, o linked list, sino que por cada capa tenemos varias neuronas. Los pesos (o parámetros) de estas conexiones ya no serían el vector \(\boldsymbol w\) sino estarían codificados en una matriz o tensor \(\boldsymbol W\).
La función de activación tiene dos roles:
- Las funciones de activación nos permiten tener multitples pendientes para distintos valores, algo que una función lineal por definición no permite.
- La función de la última capa concentra los outputs de la operación lineal en un rango de valores determinado y requerido según el problema que estamos resolviendo.
Redes neuronales y aprendizaje de características
“Attemp have been made to mechanize both of these steps (creation of concepts & weight assignment), but, to date, very little progress has been made with respect to the concept-formation step, and most of the workers have been content to supply man-generated concepts (features) and to develop machine procedures for assigning weights to these concepts” (Samuel, pag. 17)
Una de las ventajas de las redes neuronales, y de porqué Karpathy se refiere solo a redes neuronales cuando habla de software 2.0, es la capacidad de aprender representaciones de los datos. Modelos estadísticos más tradicionales se enfocan solo en el paso de la asginación de pesos, o fitting, relegando la representación de los datos como un paso previo para que el modelo pueda insumir los conceptos que habla Arthur. Por lo tanto el modelo no tiene capacidad o no se encuentra en su diseño aprender características/features de los datos. En cambio, las redes neuronales con múltiples capas tienen la capacidad de incorporar dentro del ajuste de parámetros el aprendizaje de la representación de los datos, el paso de “creación de conceptos” a la cual se refiere Arthur en la cita del comienzo de esta sección. Lo que es de gran utilidad para lidiar con datos no estructurados como imagenes o texto, cuya representación la mayoría de las veces no es trivial de construir, o en otras palabras, su feature engineering es prohibitivo. Diferencias interesantes entre deep learning y estadística más tradicional en el post “The uneasy relationship between deep learning and classical statistics”.
En el capítulo se cita y comenta el paper Visualizing and Understanding Convolutional Networks (Zeiler, Ferguson 2013) para ejemplificar lo anterior. Creo presentar este artículo es de gran utilidad porque (i) demuestra que estos modelos no son cajas negras impenetrables y (ii) es una demostración súper visual de la creación de concepto por parte de redes neuronales. Además de mostrar la expresibilidad de las capas más profundas en aprender conceptos de mayor jerarquía en base a conceptos más primitivos. Los resultados de este estudio permitieron al grupo de investigación entender mejor el modelo Alexnet que ganó la competencia Imagenet el 2012, para luego realizar modificaciones en la arquitectura del modelo, y ganar el certamen el año siguiente. Acá el abstract del paper:
Abstract: Large Convolutional Network models have recently demonstrated impressive classification performance on the ImageNet benchmark (Krizhevsky et al., 2012). However there is no clear understanding of why they perform so well, or how they might be im- proved. In this paper we address both issues. We introduce a novel visualization technique that gives insight into the function of inter- mediate feature layers and the operation of the classifier. Used in a diagnostic role, these visualizations allow us to find model architec- tures that outperform Krizhevsky et al. on the ImageNet classification benchmark. We also perform an ablation study to discover the performance contribution from different model layers. We show our ImageNet model generalizes well to other datasets: when the softmax classifier is retrained, it convincingly beats the current state-of-the-art results on Caltech-101 and Caltech-256 datasets.
Entrenar modelos con fastai y transfer learning
Este es un libro práctico y ya dentro del primer capítulo se realiza una breve demostración de como implementar un modelo de clasificación. El objetivo es identificar gatos y perros en imagenes usando la librería fastAI y el Oxford Pet dataset. Si bien la tarea es simple, lo que encontré más interesante no es el desempeño del modelo, sino la introducción de la técnica utilizada para resolver el problema, transfer learning, que esta en el core de a API. Esta técnica se basa en utilizar un modelo pre-entrenado, que ya tuvo un proceso de ajuste de parámetros, para adaptarlo a una nueva tarea. La ventaja es que ya desde el inicio contamos con capacidad instalada por el modelo anterior, lo que en algunos casos nos permite transferirla a nuestro nuevo modelo, y obtener buenos resultados sin la necesidad de contar con demasiados datos.
Al cargar los datos se hace hincapíe en el objeto path de python.
Se utiliza un dataloader que es una abstracción utilizada por PyTorch para
gestionar el dataset (i.e. minibatches, etiquetas, etc).
from fastai.vision.all import *
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224)
)ImageDataLoadeers.from_name_func() es una de las funciones constructoras
para inicializar el dataloader. Esta función en particular permite crear un dataloader
directamente de las imagenes que se encuentran en un directorio, y cuyos nombres
contienen la estructura con las etiquetas del dataset. Por lo tanto,
se recibe una función para extraer las imagenes (get_image_files), se especifica el
porcentaje del conjunto de validación (valid_pct), además de la función para
extraer las etiquetas (label_func) y el argumento item_tfms que nos
permite aplicar transformaciones a las imagenes del dataset como ajustar
su tamaño, recortarlas, entre otras.
Una vez que inicializams el dataloader podemos entrenar el modelo. El objeto
learner en la librería fastai controla el proceso de aprendizaje e insume
todos los elementos necesarios (i.e. modelo, data, optimizador, etc). Existen
learners específicos para arquitecturas conocidas como cnn_learner que es
para redes con arquitecturas con capas convolucionales. Se observa que uno de los
argumentos es resnet34 (34 por el número de capas), acá estamos especificando que
utilizaremos este modelo pre-entrenado para adaptarlo a nuestro problema. Cuando
se utiliza transfer learning no se ajustan los parámetros desde 0,
sino que aplicamos fine_tune(num_iter) para (i) ajustar los parámetros de la
cabeza del modelo, capa encargada de adaptar el modelo al nuevo problema, y
(ii) ajustar los parámetros por cada época especificada en el argumento de
la función pero con la salvedad ir ajustando con mayor velocidad los
parámetros de las últimas capas respecto a los de las primeras, lo que
tiene sentido si pensamos que las primeras capas ya fueron entrenadas.
learn = cnn_learner(dls, restnet34, metrics=error_rate)
learn.fine_tune(1)Una vez que los parámetros fueron ajustados podemos utilizar el modelo como cualquier programa, el cual recibe un input y entrega un output, este modo se conoce como fase de inferencia. Finalmente, y dado que el programa creado en este capítulo fue diseñado para resolver un problema de percepcción visual que responde a la query ¿la imagen contiene un gato o un perro?. Podríamos integrarlo dentro de otro software que, por ejemplo, deje entrar a nuestro gato abriendole la puerta del patio pero que no haga lo mismo con el perro de algún vecino.
img = PILImage.create(uploader.data[0])
is_cat, _, probs = learn.predict(img)
print(f"Es un gato?: {is_cat}.")
print(f"Probabilidad de que sea un gato: {probs[1].item():.6f}")La librería es de alto nivel y tiene abstracciones sobre el loop de aprendizaje para entrenar un modelo. Destacable que en núcleo de la API se encuentra la técnica de transfer learning.
Cuestionario
Do you need these for deep learning?
- Lots of math T/F
- Lots of data T/F
- Lots of expensive computers T/F
- A PhD T/F
Name five areas where deep learning is now the best tool in the world.
- R: Natural Language Processing, Computer Vision, Recommendation Systems, Image Generation, Text Generation.
What was the name of the first device that was based on the principle of the artificial neuron?
- R: Mark I Perceptron, desarrollado por Frank Rossenblat. Una foto de la pequeña máquina se puede ver acá.
Based on the book of the same name, what are the requirements for parallel distributed processing (PDP)?
- Un conjunto de unidades de procesamiento
- Un estado de activación
- Una función de output para cada unidad
- Un patrón de conectividad entre las unidades
- Una regla de propagación para propagar patrones de actividad a través de la red de connectividad
- Una regla de activación para combinar los inputs incidiendo en una unidad con el estado actual de esa unidad para producir un output
- Una regla de aprendizaje donde los patrones de conectividad sean modificados por la experiencia (data)
- Un ambiente donde el sistema opere
What were the two theoretical misunderstandings that held back the field of neural networks?
- R: El primer malentendido que tuvieron las redes neuronales fue por el trabajo realizado por Marvin Minsky y Seymour Papert en su libro titulado Perceptron, donde demostraron que el Percepton no era capaz de aprender funciones matematícas elementales como la función exclusive or. Sin embargo, en el mismo libro demuestran que agregando una capa adicional al Perceptron, el modelo tenía la flexibilidad de aprender cualquier función. Otro malentendido es que estos modelos son cajas negras impenetrables. Si bien presentan desafios a la hora de su interpretación, en el capítulo se da como ejemplo el trabajo Visualizing and Understanding Convolutional Networks (Zeiler, Fergus 2013) para dismitificar que las redes neuronales son modelos inescrutalbles. Este paper investigó los parámetros de la red en cada capa e identificó los features que el modelo aprendió una vez ajustado. Utilizando esta información los autores mejoraron la arquitectura AlexNet y ganaron el siguiente certamen de Imagenet el año 2013.
What is a GPU?
- R: Graphical Processing Unit (GPU). Esta pieza de hardware es útil para computar múltiples operaciones en paralelo. Dado que entrenar redes neuronales implica realizar muchas multiplicaciones y sumas, las GPU han probado ser exitosas para entrenar estos modelos.
Open a notebook and execute a cell containing: 1+1 What happens?
- R: Devuelve el resultado de 2.
Follow through each cell of the stripped version of the notebook for this chapter. Before executing each cell, guess what will happen.
- R: Done.
Complete the Jupyter Notebook online appendix (https://oreil.ly/9uPZe)
- R: Done.
Why is it hard to use a traditional computer program to recognize images in a photo?
- R: El desarrollo de un programa tradicional implica escribir las instrucciones a la máquina de manera detallada. En palabras de Arthur Samuel “Programming a computer for such computations is, at best a difficult task, …because of the need to spell out every minute step of the process in the most exasperating detail”. En tareas de percepcción, como reconocer objetos en una imagen, los humanos lo hacemos con facilidad pero a nivel subconsciente. Por lo tanto, abstraer y crear estas instrucciones requiere de un gran esfuerzo (feature engineering) y heuristicas para resolver el problema. Además varían según el contexto particular (radiografia, números) no siendo generalizables.
What did Samuel mean by “weight assignment”?
- R: Asignar valores a los parámetros del modelo. El proceso de entrenamiento de una red neuronal es simplemente un proceso de estimación o ajuste de los parámetros.
What term do we normally use in deep learning for what Samuel called “weights”?
- R: El término más utilizado en la actualidad es el de parámetros (i.e. especificado en la mayoría de los frameworks actuales).
Draw a picture that summarizes Samuel’s view of a machine learning model.
Why is it hard to understand why a deep learning model makes a particular prediction?
- R: Todo modelo estadístico enfrenta dificultades para comprender las predicciones a medida que la complejidad del modelo aumenta (i.e. más parámetros y capas) y cuando los datos sobre los que el modelo se encuentra operando difieren de manera importante respecto con los que fue entrenado (i.e. distribution shift). Sobretodo vimos que una de las ventajas de las redes neuronales es su capacidad modular de crecer incorporando capas y diferentes arquitecturas, pero esto tambien dificulta la interpretabilidad de las predicciones. Siempre se debe ser cauto con la interpretabilidad y afirmaciones sobre las capacidades de un modelo, y aplicar varios métodos para inspeccionar y ver el funcionamiento interno de los parámetros.
What is the name of the theorem that shows that a neural network can solve any mathematical problem to any level of accuracy?
- R: El nombre del teorema es Universal Approximation Theorem. El siguiente video de Michael Nielsen es una explicación visual sobre este teorema:
What do you need in order to train a model?
- R: Del diagrama de más arriba podemos inferir que para entrenar un modelo necesitamos datos (elipses azules), y por esto se entiende el input (e.g. imagen, texto, características tabularizadas) y etiquetas de buena calidad, sin esto último el mécanismo de feedback, compuesto por la función de costo (elipse morada) y la regla de actualización, no puede guiar el ajuste de los parámetros (elipse café). Se requiere una forma funcional del modelo (aka arquitectura) para realizar las predicciones (elipses rosadas) en base a los inputs, las cuáles el mécanismo de ajuste contrastará respecto a las etiquetas. Una vez que el modelo fue entrenado, tenemos un programa que recibe inputs y entrega outputs, el cual puede utilizarse como componente dentro de cualquier software.
How could a feedback loop impact the rollout of a predictive policing model?
- R: El modelo se ajusta a partir de datos. Si el modelo indica predicciones para que las policias se focalicen en cierto sector geográfico, con mayor probabilidad aumentaran los arrestos e incidentes registrados en esa zona debido a la focalización de actividades de patrullaje policial. En consecuencia, habrá un mayor número de información adicional de esa zona cuando se incorporé nueva información al modelo. Al volver ajustar el modelo, los ajustes de parámetros reforzaran la relación de criminalidad en ese sector, aumentando el número de predicciones y respaldando las acciones policiales definidas. Y así obtenemos un positive feedback loop, mientras más usamos el modelo mayores sesgos producimos en los datos.
Do we always have to use 224x224 pixel images with the cat recognition model?
- R: La dimensión de 224x224 responde a razones historicas cuando se diseño una arquitectura en particular. Es posible aumentar la resolución de la imagen y asi el modelo capturará mayor información, pero a un costo computacional mayor. De manera contraria, menor resolución implica una disminución en el desempeño del modelo, pero mayor eficiencia computacional. Otra razón historica a la hora de entrenar redes neuronales son que el tamaño de los batch aumenta en potencias de 2, ver No, We Don’t Have to Choose Batch Sizes As Powers of 2 (Sebastian Rashcka). Además de la influencia de los random seeds para entrenar modelos, “Torch.manual_seed(3407) is all you need: On the influence of random seed in deep learning architectures for computer vision” (David Picard).
What is the difference between classification and regression?
- R: La diferencia entre los problemas de clasificación y regresión tiene que ver simplemente con el tipo de variable de respuesta que estamos modelando. Si es una variable discreta (i.e. perro, gato, nivel socioeconomico) es un problema de clasificación. En cambio, si la variable de respuesta es continua (i.e. salario) es un problema de regresión.
What is a validation set? What is a test set? Why do we need them?
- R: El conjunto de validación se utiliza para computar métricas durante el entrenamiento del modelo. Recordar que las métricas son de consumo humano. Además el conjunto de validación nos permite probar distintas configuraciones del modelo especificadas por los hiperparámetros. En cambio, el conjunto de pruebas, o test set, es un conjunto de datos reservado exclusivamente para reportar la performance final de nuestro modelo, una vez que se probaron todas las ideas e iteraciones de experimentos.
What will fastai do if you don’t provide a validation set?
- R: La librería
fastaiautomáticamente separa el dataset en 80/20, separando un 20% de los datos para el conjunto de validación. Si se requiere cambiar este porcentaje se debe especificar en el argumentovalid_pctdel dataloader.
- R: La librería
Can we always use a random sample for a validation set?
- R: No siempre se debe usar un conjunto de validación aleatorio. La mayor importancia tanto del conjunto de validación como el conjunto de prueba es que sean representativos de datos futuros que no hemos visto. Y tomar un conjunto de datos y obtener una fracción de manera aleatoria no siempre es la respuesta. Imaginemos el caso de series de tiempo, no tiene mucho sentido tomar una muestra aleatoria del dataset para construir el conjunto de validación, pero si tiene sentido aislar una parte final de la serie para evaluar el modelo simulando datos futuros nunca antes visto. Otro ejemplo tiene que ver con posible redundancia en las observaciones que de no aislarlas apropiadamente, el modelo obtenga buenos resultados en el conjunto de validación solo porque ha memorizado ciertas características de este grupo de observaciones particulares, en vez de encontrar un patrón general. Por ejemplo, si tenemos la misma mascota en diferentes fotos del dataset, lo correcto sería que todos los ejemplos de esa mascota queden aislados en un mismo conjunto y no en separadas en ambos conjuntos.
What is overfitting? Provide an example.
- R: El sobreajuste de un modelo se refiere al fenómeno cuando el modelo comienza a memorizar el ruido, o parte “idiosincrática” del conjunto de datos destinado al entrenamiento, tomando en cuenta efectos particulares del dataset en el ajuste de sus parámetros y no realizando ajustes que capturen patrones generalizables en los datos. El objetivo es entrenar un modelo que obtenga un buen desempeño en datos nunca antes vistos y no memorizar perfectamento los datos de entrenamiento. Por ejemplo, si utilizamos un modelo para predecir el precio de viviendas, y el modelo durante el entrenamiento se sobreajustó, sus parámetros reflejaran condiciones particulares del grupo de viviendas utilizadas para ajustar el modelo y no un patrón generalizable sobre los fundamentos en los precios de la vivienda que sean de utilidad para cualquier otra vivienda que no se encuentre en el dataset. El modelo tendrá peor desempeño en viviendas que no se encuentren en los sectores cubiertos dentro del conjunto de entrenamiento, o que sus características difieran respecto a los rangos de valores en las características de las viviendas de entrenamiento.
What is a metric? How does it differ from loss?
- R: Una métrica sirve para medir el desempeño del modelo según algún objetivo como nivel de error, precisión, sesgo en las predicciones, o alguna métrica especifica de negocio (KPI). En otras palabras, las métricas son de consumo humano, y están estrechamente relacionadas con el problema que se busca resolver. En cambio, la función de costo esta diseñada para el proceso de ajuste de los parámetros del modelo. Es parte del mécanismo de retroalimentación automático del modelo. Por ejemplo, que la función de costo haya disminuido 20% en 100 iteraciones no nos dice nada respecto a si estamos identificando mejor las transaccions fraudulentas dentro de la red de pagos, pero la historia es diferente si nuestro accuracy mejoró 20%. Algo que si nos garantiza la función de costo es un mécanismo de retroalimentación respecto a las predicciones del modelo según un estado particular de parámetros (i.e. set de valores), y efectuar los cambios pertinentes de estos en la dirección que minimiza la función de costo. Por esta razón, la función debe cumplir ciertas propiedades como ser diferenciable, eficiente en computar, etcétera. En conclusión, la función de costo es para el computador y la métrica para el humano.
How can pretrained models help?
- R: Un modelo pre-entrenado ya paso por un proceso de ajuste de parámetros, por lo que cuenta con algún grado de capacidad que permite acelerar el aprendizaje en nuevos datos. Estas capacidades en el mejor de los casos pueden ser características, o features, que el modelo derechamente ya aprendió y pueden ser generalizables. Por ejemplo, en el caso de un problema de clasificación de imagenes, disponer de una característica que ya identifica “esquinas” siempre será de utilidad, y es algo que se puede reutilizar. En un caso no tan óptimo, un modelo pre-entrenado puede verse como una partida en caliente para el nuevo proceso de ajuste y proveernos de una buena inicialización de parámetros versus una inicialización completamente aleatoria.
What is the “head” of a model?
- R: La cabeza del modelo es la última capa que se agrega a una arquitectura de un modelo pre-entrenado especifica para el dataset que estamos trabajando. Cuando utilizamos un modelo pre-entrenado, debemos adaptar la capa final de la arquitectura del modelo a las dimensiones del output del problema que queremos “transferir” el modelo. Por ejemplo, si el modelo pre-entrenado fue ajustado en el dataset ImageNet el cual busca identificar 1000 categorías y nuestro problema solo requiere distinguir entre dos, debemos adaptar la cabeza del modelo a una salida de largo 2.
What kind of features do the early layers of a CNN find? How about the later layers?
- R: Los features de las primeras capas son más primitivos, o básicos, como texturas, gradientes o esquinas. En cambio, a medida que vamos avanzando en las capas, los features que aprende la red van siendo de mayor nivel como figuras geometricas, caras, etcétera. Una explicación de esto tiene que ver con las capas convolucionales, las cuáles son capas volumétricas que despliegan varios filtros o kernels que se especializan en una misma región de pixeles (aka receptive field), aprendiendo conceptos y aprovechando la estructura de “localidad” de la imagen: pixeles más cercanos tinen mayor relación que pixeles más distantes. Además, entre capas convulocionales, este tipo de arquitecturas suelen utilizar una capa de pooling, básicamente es una técnica de downsampling, reduciendo imagenes por ejemplo de 28x28 a 14x14 compactando los pixeles de la imagen a través de una operación de agregado, lo que luego, al aplicar otra capa convolucional tiene el efecto de aumentar la cobertura de los nuevos kernels sobre la información de la imagen, aumentando su receptive field. De esta forma las últimas capas comienzan aprender conceptos de mayor jerarquía al relacionar distintas regiones iniciales que los filtros observaban y a construir en base a los conceptos más primitivos.
Are image models useful only for photos?
- R: No, se puede utilizar modelos de imagen para todo problema que se pueda reformular como una imagen (e.g. sonido-a-espectogramas). Regla general, si un humano es capaz de interpretar un gráfico de cierto fenómeno que no es un problema inherente de imagen, es probable que una arquitectura diseñada para modelos de imagenes funcione bien.
What is an architecture?
- R: Las redes neuronales son funciones. La arquitectura es la forma funcional que toma una red neuronal, la cual esta compuesta por las diferentes capas y conexiones descrita en los parámetros. En la imagen a continuación se preseneta la forma funcional del modelo que ganó la competencia ImageNet 2012, llamada AlexNet:

What is segmentation?
- R: Es un problema dentro del campo de visión por computadora que consiste en identificar el contenido al que pertenece cada pixel dentro de una imagen (i.e. autos, semaforos, peatones, etc).
What is
y_rangeused for? What do we need it?- R: Sirve para especificar el rango de la variable de respuesta cuando el problema es de regresión, es decir, tenemos una variable de respuesta tipo continua.
What are hyperparameters?
- R: Los hiperparámetros son variables que controlan algunos aspectos sobre el proceso de entrenamiento del modelo. Por ejemplo, la cantidad de regularización o la magnitud de la tasa de aprendizaje. Son parámetros sobre parámetros dado afectan el ajustes sobre los parámetros de una u otra forma.
What’s the best way to avoid failures when using AI in an organization?
- R: Siempre diseñar y crear un buen conjunto de validación para evaluar correctamente la generalización de los modelos. Si se trabaja con terceros, quienes se les encargará resolver un problema utilizando modelos ajustados en base a datos, siempre guardar un conjunto de prueba que no hayan visto los proveedores. Así tendremos capacidad para diagnosticar correctamente el desempeño del modelo. Otro punto importante es paralelamente elaborar un buen modelo base para saber de antemano el posible potencial de mejora utilizando modelos más complejos para resolver el problema.
Further Research Questions
Última actualización: 09/07/2022
Why is a GPU useful for Deep Learning? How a CPU is different, and why is it less effective for deep learning?
Hay una charla realizada por Stuart Oberman, vicepresidente de NVidia, en Stanford realizada el 2017 que da un buen overview acerca sobre las GPU: Nvidia GPU Computing: A Journey From PC Gaming to Deep Learning (slides de la presentación).
GPU computing se divide en dos grandes grupos:
- Simulación: drug design, options pricing, wheather forecasting
- Visualización: seismic imaging, automotive design, medical imaging
NVIDIA introdujo la GPU en 1999, un único procesador para acelerar juegs de video y gráficas 3D.
Objetivo: acercarse a la calidad de imagen de estudios de video renderizadas de manera offline , pero en tiempo real. Esto significa millones de pixeles por frame, > 60 frames por segundo. Uso de largos arrays de floating points para explorar paralelismo a lo ancho y profundo.
El modelo G80 fue la primera GPU que introdujo un procesador unificado para sombras (unified shader processor). Todas las etapas de sombra usan el mismo set de instrucciones y se ejecutan en la misma unidad: streaming multiprocessor (CUDA).
CUDA: C++ for throughput computers, on-chip memory managmenet, asunchronous, parallel API, programmability makes it possible to innovate.
La slide número 22 hace una comparación interesante entre el paradigma que guia un GPU versus a un CPU:
Latency Oriented: - Fewer, bigger cores with out-of-order, speculative execution - Big caches optimized for latency - Math units are small part of the die
Throughput Oriented - Lots of simple compute cores and hardware scheduling - Big register files. Caches optimized for bandwidth. - Math units are most of the die
Definiciones de los conceptos anteriores según el libro Designing Data-Intensive Application de Martin Kleppmann:
Throughput
Throughput is the number of records we can process per second, or the total time it takes to run a job on a dataset of a certain size
Latency
Latency is the duration that a request is waiting to be handled – during which it is latent, awaiting service
Response time
Response time is what the client sees: besides the actual time to process the request (the service time), it includes networks delays and queueing delays
Pascal GP100: primer modelo de NVIDIA adaptado para Deep Learning, 21 TFLOPS fp16 for Deep Learning training and inference acceleration. Primera vez que se agrega datatype fp16 con el objetivo de acelerar el entrenamiento e inferencia de modelos de Deep Learning.
Tensor Core: matriz de precision hibrida. FP16 para AB y acumula con FP32 (o FP16).
Try to think three areas where feedback loops might impact the use of machine learning. See if you can find documented examples of that happening in practice.
TODO…